자료구조
✨자료구조에서는 데이터랑 연산이 꼭 필요함
선형 자료구조(Linear Data Structure)
: 데이터 요소를 순서대로 정렬
✨ 개별 요소에 접근하는 작업에는 선형 자료구조가 더 효율적.
선형 자료구조에서는 첫 번째 요소가 마지막 요소까지 백트래킹(Backtracking)없이 순회할 수 있지만, 비선형 자료구조에서는 종종 되돌아가야 함.
배열(Array)
배열의 가장 큰 특징은 인덱스 (추가, 삭제, 삽입, 수정)
✨특징
- 선형 자료구조(1차원 자료구조)
- 모든 요소는 동일한 데이터 타입을 가짐
- 정적 자료구조 : 크기가 고정되어 있는 자료구조
- 각 요소는 하나의 인덱스에 매핑
- 고정된 크기를 가짐
- 연속된 메모리 블럭에 할당(메모리 한 칸의 크기가 모두 동일함)
- 정렬되어있기 때문에, 빅오 속도를 더 빠르게 할 수 있음 (O(log n) -> 이분탐색
- 기본적으로 시간복잡도 O(1)
✨시간복잡도 연산
삽입/수정/삭제 ==> O(n)
연결 리스트(Linked list)
연결리스트는 인덱스가 없음. 첫 번째 노드의 값을 읽어서 다음 노드의 주소를 찾아야 됨
메모리 안에 랜덤하게 배정하여 노드가 그 주소를 가지고 있음.
✨특징
- 선형 자료구조(1차원 자료구조)
- 모든 요소는 동일한 데이터 타입을 가짐
- 동적 자료구조 : 크기가 바뀔 수 있는 자료구조
- 첫 번째 노드의 주소만 알고 있음
- 가변 크기를 가질 수 있음
- 비연속된 메모리 블럭에 할당
- 연결리스트는 불연속이라 빅오가 더 빨라질 방법은 없음
파이썬은 배열과 연결리스트 특징을 모두 가지고 있음
그래서 동적 배열이라고 부름.(Dynamic Array)
비선형 자료구조(Nonlinear Data Structure)
: 데이터를 비연속적으로 연결
트리(Tree)와 그래프(Graph)
트리는 계층 구조가 있는 가계도, 조직도에 주로 쓰임
그래프는 SNS와 같이 한 사람의 영향력을 네트워크처럼 표현
트리를 연산할 때 필요한 것 : 추가, 삭제, 수정, 정렬, 탐색(계층 아래까지 갔다가 다음 계층으로 이동해서 아래로 팜)
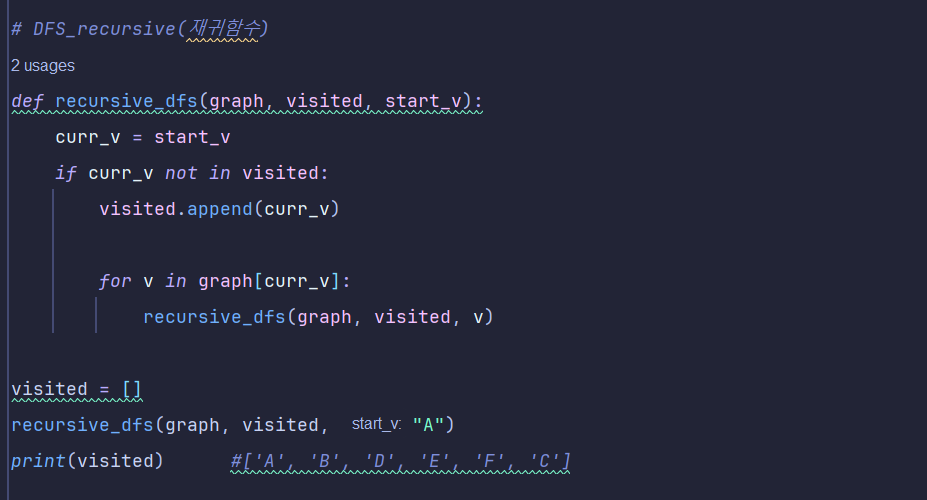
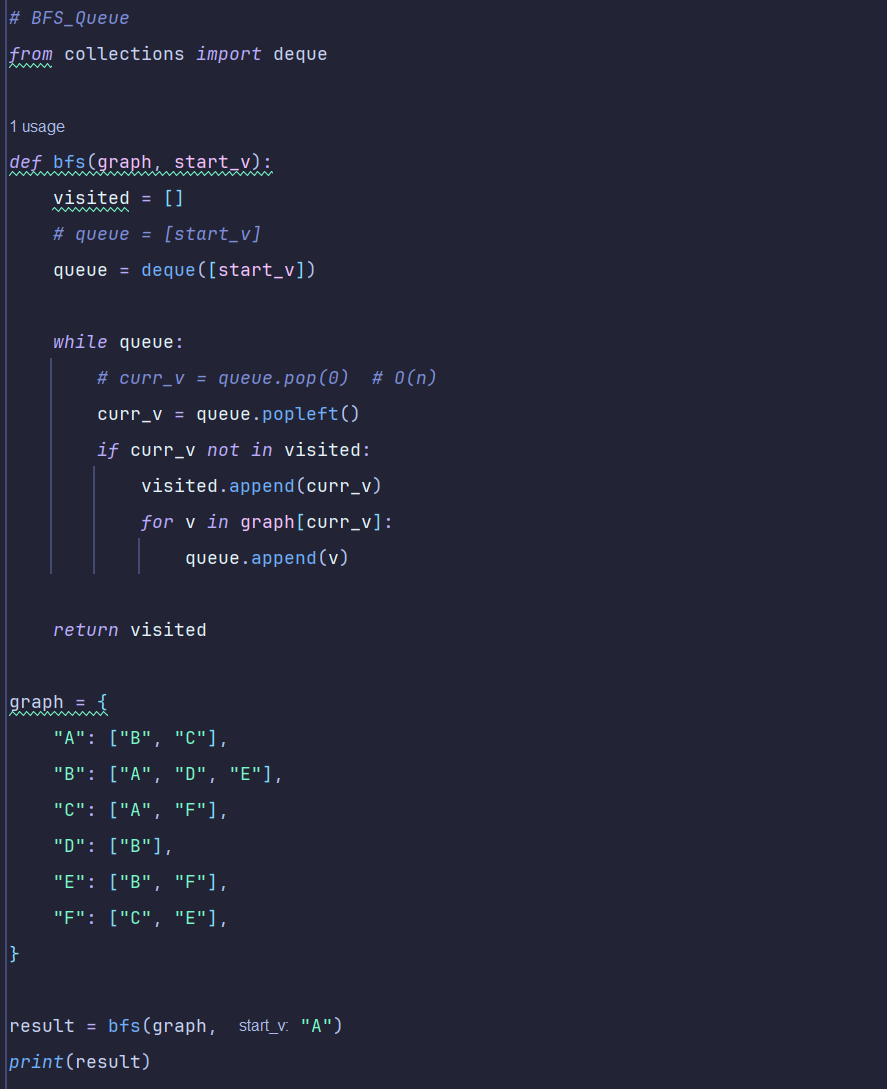
그거를 DFS(깊이 우선 탐색), BFS(너비 우선 탐색) -> 탐색하는 알고리즘
트리랑 그래프 자료구조에서 대표적인 알고리즘이 dfs, bfs 임
Search or Retrieve
Search : 검색하다
get an index from an element
- 보통 특정 원소(요소)의 위치(인덱스)를 찾는 과정.
- 위치(인덱스)를 알고 있지 않음
- 찾는 것
✨ 선형 탐색 : 정렬되지 있지 않은 배열에서 for문으로 하나씩 돌면서 인덱스 값 도출
✨ 이진 탐색(이분 탐색) : 정렬된 배열에서 가능, 이분 즉 반씩 범위를 좁혀가며 인덱스 값 도출
분할 정복 기법 (이 안에 이진 탐색이 들어감)
: 큰 문제를 작은 문제들로 쪼개서 작은 문제들을 해결하는 것으로 큰 문제를 해결하는 기법, 3가지
- divide : 큰 문제를 작은 문제로 쪼갬
- conquer : 작은 문제들에서 결론을 도출해내는 과정 (재귀로 띄고 있는 경우가 많다)
- combine(optional) : 있을수도 있고, 없을 수도 있음
✨ 대표적인 분할 정복 예시 (토너먼트): 이분 탐색, 병합 정렬, 퀵 소트
### 알고리즘 공부하려면 토익처럼, ⓐ문자열(회문, 파문) ⓑ배열 순회
Retrive : 검색하다(가져오다)
get an element from an index
- 특정 인덱스나 위치에서 해당하는 원소(요소)를 가져오는 과정
- 이미 인덱스나 위치를 알고 있음.
- 가져오는 것
'알고리즘' 카테고리의 다른 글
| 시간 복잡도와 공간 복잡도 (0) | 2024.08.07 |
|---|---|
| 그래프: DFS, BFS로 탐색하는 방법 (0) | 2024.08.01 |
| 자료구조_그래프 +)신장트리, 최소신장트리 (0) | 2024.07.31 |
| 자료구조_트리 (0) | 2024.07.29 |
| 알고리즘 기초_stack(스택) (0) | 2024.07.11 |